
During my tenure at my previous company, we converted a big monolith based trading system into micro-services based architecture. It required a base infrastructure to orchestrate communication between all services. Instead of using an out-of-the-box solution like Redis, we created our own distributed cache from scratch. This cache was primarily a server-client cache, where-in server holds the main copy of data while distributing it to clients on need basis.
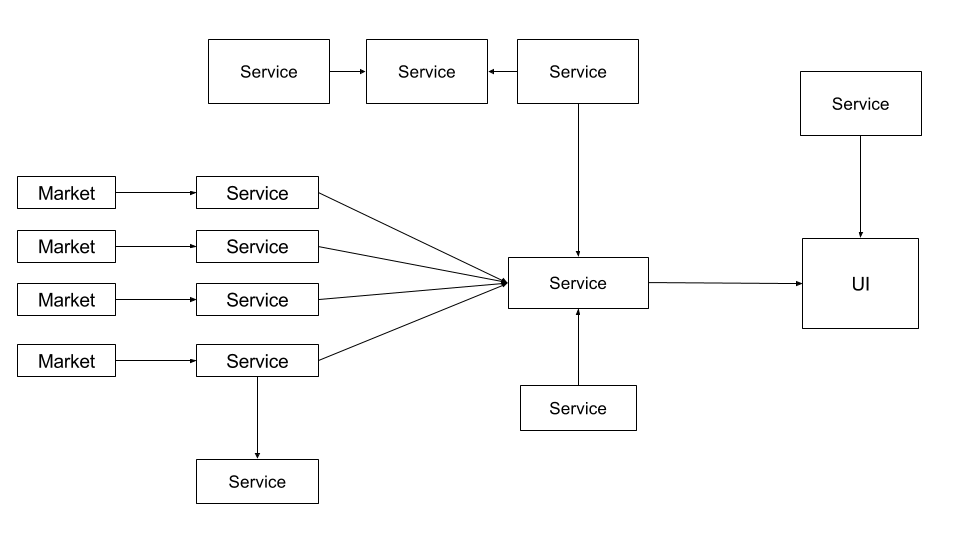
Building blocks
- Connectivity (TCP based)
- Service Discovery
- Data serialization
- Caching framework
- Remote Procedure Call
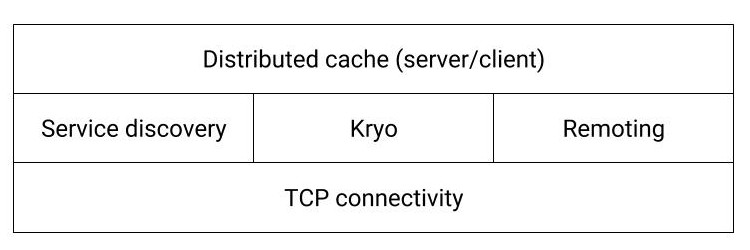
TCP Communication - Grizzly
The base of the communication infrastructure, TCP library was needed to establish and maintain connections between 2 or more services. We chose Grizzly out of many networking libraries available for java. It performed relatively well.
- Connection pool: Grizzly allows to tweak the thread pool for connections (useful for throughput). Though we made the pool size configurable, we didn’t ever need to tweak it for any particular service. Default pool size was kept at 4
- Data: Kryo module was initially used directly for marshalling/unmarshalling of data. Later it was moved into its own module and exposed via strategy pattern.
- Data Listeners: Once data was unmarshalled, it was passed to caching layer using data listeners.
- Heartbeats: Connectivity status was monitored in real-time using heartbeats mechanism.
- Connection Listeners: We added listeners for disconnect, re-connect, and heart-beat events. These listeners was exposed to the top most module (caching) using delegation. This was especially useful in alerting services disconnected from market.
- Retries: If disconnected, retries were done at regular intervals (of 5 seconds). Interval was configurable based on priority of application.
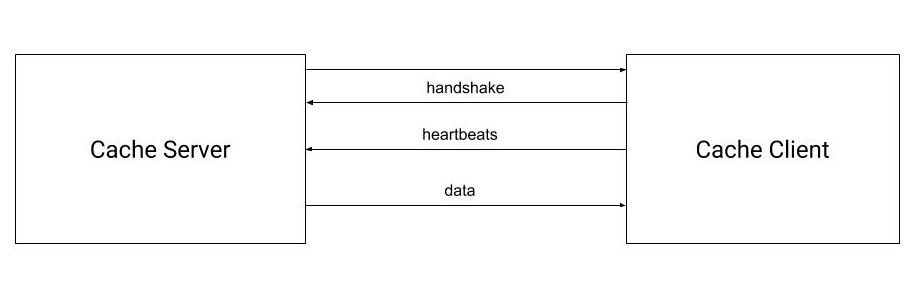
Service Discovery
- Well known service: The host-port information of the server caches were not hardcoded. Instead, they were configured with proprietary well-known service similar to zookeeper.
- Naming: Service configuration look up was done using name of the cache (eg: securities-cache, customer-cache etc)
- Configuration: In addition to the host and port information, the config contains various parameters like connection-pool size, retry-interval etc.
- Fallback: The service was created and maintained by Nomura architecture team and hardly ever had downtime. Thus we did not create fall back for this. Also, the service was needed only during startup, thus reducing probability of failure further.
Data serialization - Kryo
- Speed: Out of many libraries available in java, we chose Kryo mainly because of its serialization speed.
- Binary: Though Kryo is fast, it is a binary protocol. This means, during Production issues, the data had to be copied from logs, and run through java deserializer class to make sense of the data. Considering 85% of a project’s time is spent in maintenance, this factor weighed heavily against us.
- Special classes: There were a few classes (eg: Joda DateTime) which had to be configured in Kryo configuration to be serialized correctly.
- Kryo Net: Kryo Net was soon released as a TCP/UDP networking library which works excellently with Kryo. In hindsight, choosing it would have helped save lot of effort in maintaining TCP communication layer.
Remoting
- Use case: Implementing remoting was fairly easy once the building block of TCP connection was established. This utility was necessary to implement Lazy cache detailed below.
- Sync: Synchronous RPC was simple to design. Every server class which could which implemented a specific interface & method could be called remotely. The implemented method returned service-name string. On startup, TCP module created a HashMap of these service-names and the instance as key-value. Every client request contains service-name to be called along with method to be called and corresponding parameters. Server’s job was then to get instance from the HashMap and call the method with parameters using reflection.
- Async: Asynchronous RPC call was slightly trickier. It involved exchanging a unquie (UUID) for every method call request. When the method was finished executing, server sends returned response object to the client with the same UUID, so as to map the request-response.
Caching
- CQ Engine: We chose CQEngine instead of normal HashMap for saving data. CQEngine is quite stable and contains lot of good features like indexing, querying etc and great speed.
- Indexing: CQEngine allows indexing objects with particular variables and attains O(1) performance while querying.
- Queries: CQEngine also has querying abilities almost as feature rich as SQL
- Snapshot ready event: Once client connects to server cache, it starts receiving the initial snapshot data from server. Once the entire snapshot data is received, a ready event is fired, allowing application to start its working.
- Realtime data: After initial snapshot is received, client can start receiving data in real time. Whenever Server cache receives new data it pushes the same to all clients using TCP module.
- Add/Delete/Update events: The data events are of add/delete/update types.
- Dirty cache: Due to distributed nature of cache, there is a possibility client cache disconnects with server (network issues or if server is down), and still has data in its cache (aka dirty cache). Such state of cache was acceptable in most cases, and was known using connection listeners exposed by TCP module.
Application use-cases
- Default server client cache: Default caching which uses server-cache which stores golden copy, and 1 or more clients which receive data in form of initial snapshot and then real-time updates.
- Filter based cache: Server client cache which allows client to subscribe to a certain kind of data (based on filter). Though, we implemented this filtering on caching module in client cache, thus it did not save bandwidth though it made server code cleaner.
- Streaming cache: Form of client which does not store data in CQEngine, it just receives data from server. Helpful in services like auditing.
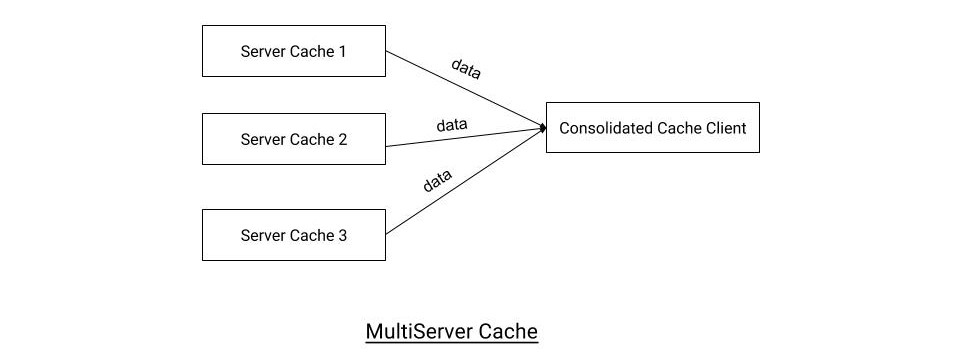
- Multi cache: Form of client which connects to multiple cache servers at once. Helpful in services which connect and process trades from multiple markets.
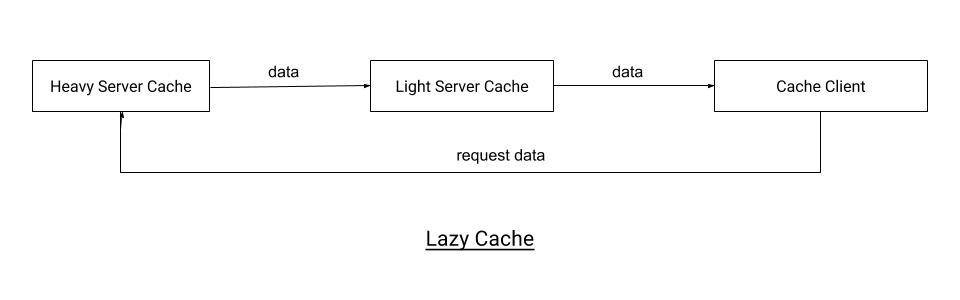
- Lazy cache: Form of cache where if server cache shares only requested data with client. This is implemented simply by using 2 server caches off which 1 stores entire copy, while other stores only data requested by client cache. Client requested the required data using remoting.
IKVM experiment
This Java based system of distributed cache formed a strong base for our microservices. Though, since our UI was implemented in .NET we could not extend this system to trader UI. We attempted to fix this by using IKVM, which converts Java classes into dot NET ones. Unfortunately IKVM was not mature and stable enough to convert all JARs/modules in .NET. Thus the experiment remained unsuccessful.
Tags: